")
")
Open Access
Table 2
Comparison between GD and SGD.
| Gradient Descent | Stochastic Gradient Descent |
|---|---|
 |
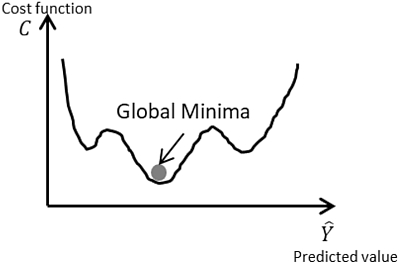 |
| GD computes gradient using a batch from the dataset | SGD computes gradients using single rows of training examples |
| It follows a deterministic approach | It follows a random approach |
| It converges slower on large training samples | It converges faster on large training samples |
|
Steps:
For every iteration – Traverse entire dataset – Evaluate gradient – Return |
Steps:
For every iteration – Iterate over each value in the dataset – Evaluate Gradient – Return |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.